© 2025-2026 Dariusz Korzun Licensed under CC BY-NC 4.0
Last updated February 8, 2026
Defining AI — Scope and Boundaries¶
The Definitional Problem¶
Artificial intelligence is powerful. Genuinely, transformatively powerful. But power without clear boundaries is risk.
Picture a conference room in a major city: fluorescent lights humming overhead, a projector casting slides onto a white wall, executives leaning forward with pens hovering over contracts. They're about to commit millions to an "AI initiative." They sign. They launch pilots. They reorganize entire teams. And yet, if pressed, not one person in that room could offer a precise definition of what they just bought.
This scene plays out constantly. The confusion starts here, at the foundation. When the definition is fuzzy, expectations drift. Roadmaps fracture. Budgets evaporate.
Artificial Intelligence isn't a single invention. It's not some solitary breakthrough that occurred in a laboratory somewhere. It's a family of four distinct philosophies that have competed for dominance over the past seventy years—each with its champions, its funding cycles, its winters of discontent, and its moments of vindication.
Each philosophy implies different system architectures, different talent requirements, different risk profiles, and different governance models. Clarity in definition isn't academic. It's the first line of defense.
Stuart Russell, a computer science professor at Berkeley whose office overlooks the hills of the East Bay, and Peter Norvig, who spent years directing research inside the Googleplex in Mountain View, first articulated a useful framework for organizing these philosophies in Artificial Intelligence: A Modern Approach. The textbook, now in its 4th edition from 2020 (Amazon), became the most widely adopted AI textbook in history—the book that trained generations of researchers from Cambridge to Shanghai.
Russell and Norvig arranged the competing schools along two axes.
- One axis poses a fundamental question: Is the goal to behave like a human, or to behave rationally? These are profoundly different objectives with profoundly different consequences.
- The second axis asks: Are we concerned with the internal thought process, or only with observable external behavior?
This framework yields four classical schools of thought, each carrying its own intellectual history and its own practical relevance.
The Four Schools of AI¶
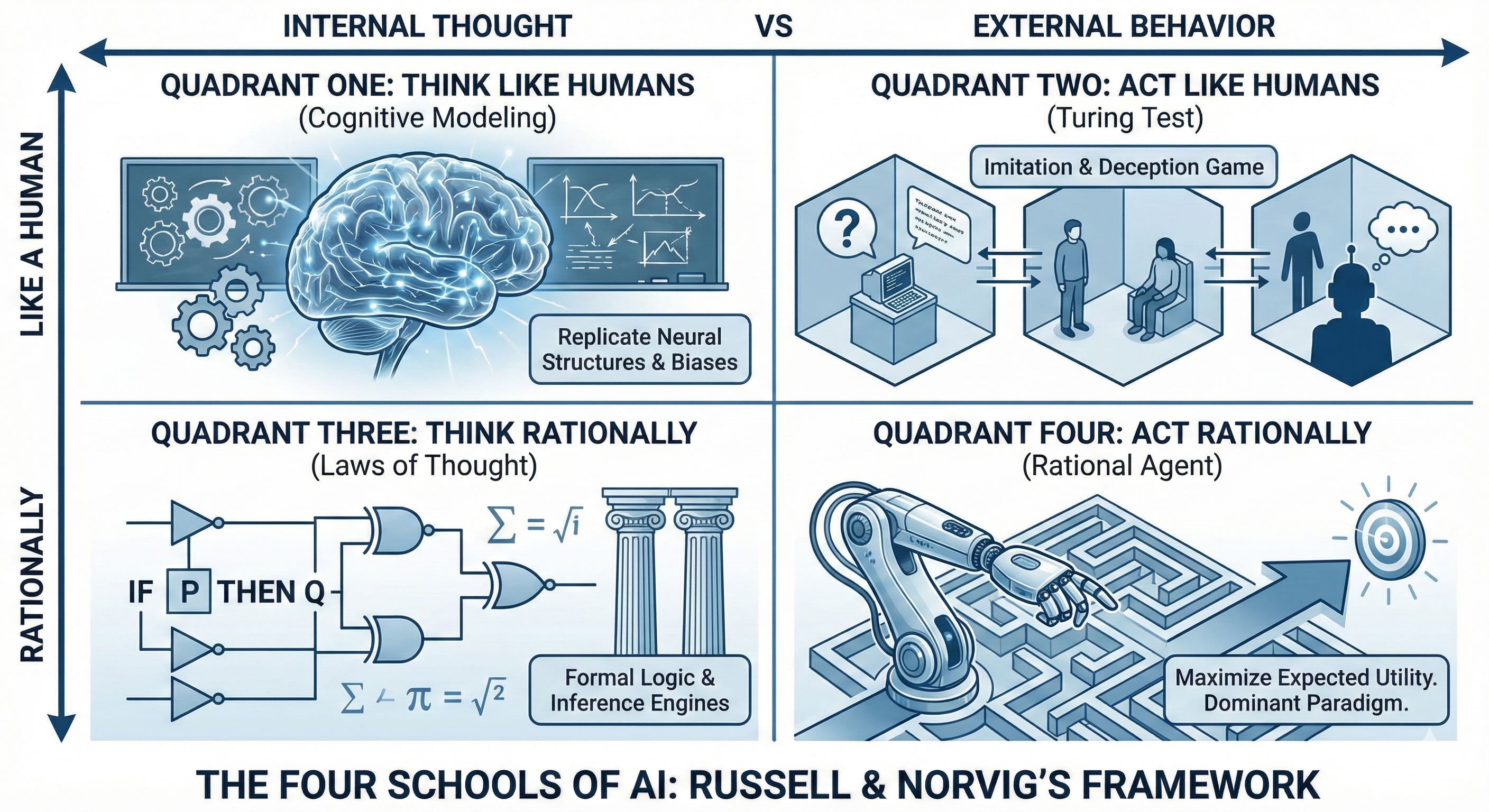
Quadrant One: Systems That Think Like Humans¶
The first quadrant is cognitive modeling—the domain of cognitive science. The objective: to understand and replicate how people actually think, neural structure by neural structure, biases and all.
Researchers in this tradition draw from psychology, neuroscience, and cognitive theory to build models that mirror human reasoning patterns. In the 1970s and 1980s, at Carnegie Mellon and other universities, teams developed architectures like ACT-R and SOAR. Allen Newell, working in a cramped office filled with chalkboard diagrams of the mind, pursued what he called "unified theories of cognition"—a single computational framework that could explain how humans remember, decide, and solve problems.
This approach has value for science. It helps test theories about the mind. But it's far less valuable as a design blueprint for scalable systems. Replicating human biases and biological limitations isn't how you build durable advantage. Engineering against human flaws doesn't scale.
Quadrant Two: Systems That Act Like Humans¶
The second quadrant follows the Turing Test approach.
In 1950, Alan Turing—a thirty-eight-year-old British mathematician by then famous for cracking the Enigma code at Bletchley Park during the war—published a paper titled "Computing Machinery and Intelligence" in the journal Mind. In it, he posed a deceptively simple question: Can a machine fool a human interrogator into believing it's human?
Turing imagined a game. An interrogator sits in one room, communicating via typewritten messages with two correspondents in separate rooms—one human, one machine. If the interrogator can't reliably tell which is which, the machine passes. The focus is on imitation—matching human conversation styles, timing, and quirks closely enough to pass as a person.
Precision matters here. The Turing Test isn't a test of intelligence. It's a test of deception. The criterion is imitation, not capability. A system optimized to pass this test is optimized to mislead—not necessarily to perform useful work. For a real-world system, "fooling" the user is rarely the optimization metric that matters. Imitation isn't a strategy.
Quadrant Three: Systems That Think Rationally¶
The third quadrant takes the "laws of thought" approach—an attempt to codify perfect reasoning using formal logic.
This tradition traces back centuries, to Aristotle's syllogisms and Leibniz's dream of a calculus ratiocinator—a universal language of thought that could settle all disputes through calculation. The tools are inference engines, theorem provers, and logical calculus. You specify axioms and inference rules, then the system derives correct conclusions.
The ambition is elegant. But the real world creates problems. Pure formal logic is brittle; it shatters the moment it encounters ambiguity, incomplete information, or genuine uncertainty. Real operating environments are noisy, messy, and largely unwritten. Intelligence, it turns out, isn't purely logical.
Quadrant Four: Systems That Act Rationally¶
The fourth quadrant is the dominant paradigm in modern AI.
The rational agent approach abandoned the obsession with mimicking human thought. It stopped caring whether the machine "thinks" in any recognizable sense or whether it convincingly imitates a person. Instead, it focused on a single, sharper question: given what the system can perceive and do, which action will best advance its goals?
An agent perceives its environment and takes actions that maximize expected utility—the best possible decisions given available information. The shift: from imitation to effectiveness. This isn't philosophy. This is engineering.
The 4th edition of Russell and Norvig's textbook from 2020 contains a critical update: the authors now emphasize that objectives may not always be fixed or fully known to the agent. This isn't a minor technical point—it's the foundation of the AI alignment challenge. A truly rational agent must account for uncertainty about what humans actually want, not just optimize blindly for a stated objective. This evolution in the definition reflects the field's maturing understanding of the risks of misaligned optimization.
The Working Definition¶
A precise, operationally useful definition follows:
Artificial Intelligence is the study and construction of agent systems that perceive their environment and take actions that maximize their chances of success at achieving specified goals.
This isn't a slogan; it's an engineering specification. Every word does work.
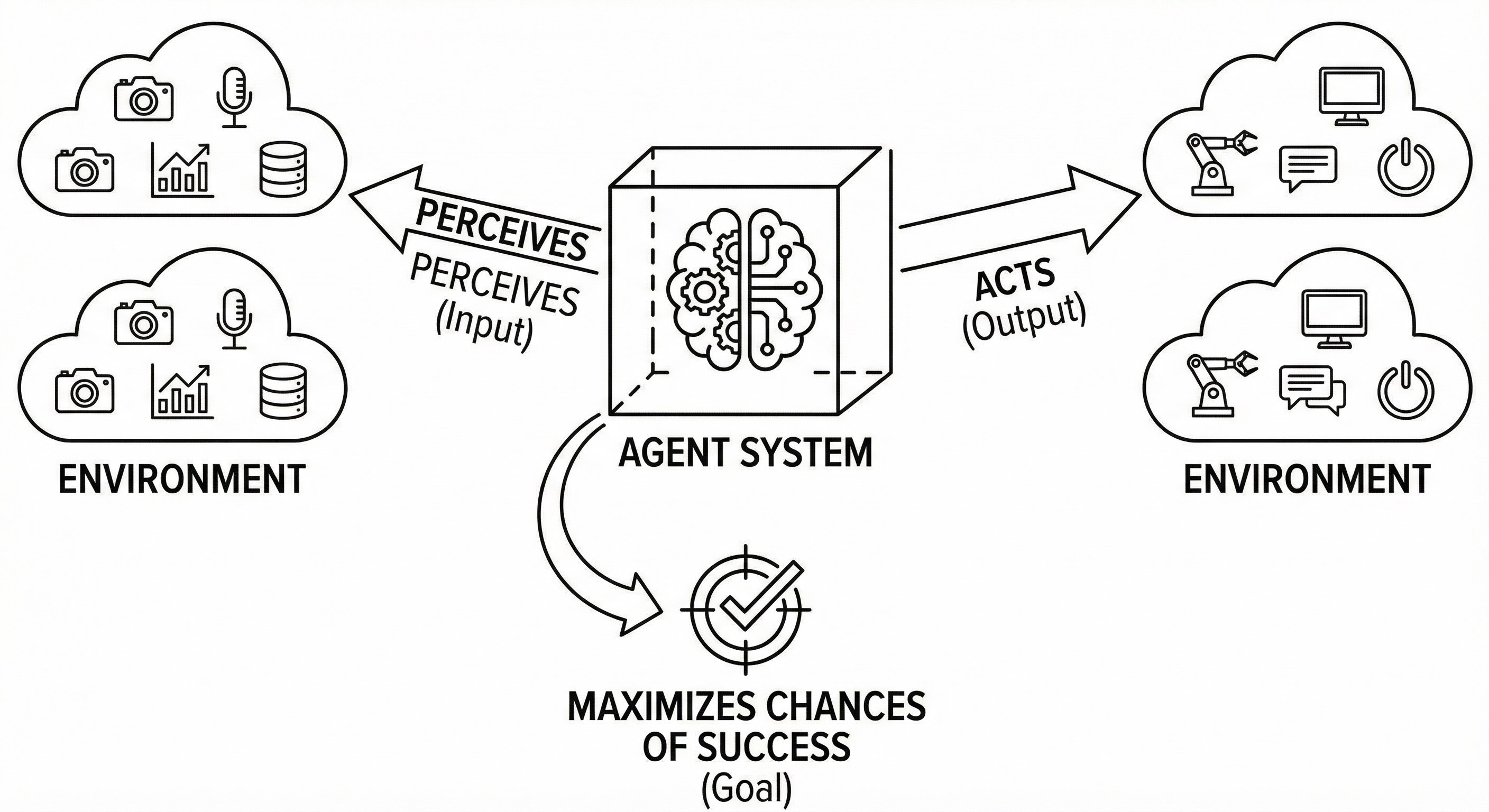
Agent: the system itself—the entity built or bought. It could be a trading algorithm executing microsecond decisions in a data center, a customer service assistant fielding questions through a chat window, a recommender suggesting the next video on a phone, a routing optimizer rerouting delivery trucks around a traffic jam in real time. The agent operates in an environment.
Environment: everything the agent can sense and potentially influence. Data feeds streaming market prices, APIs connecting to payment systems, physical devices on factory floors, markets fluctuating with supply and demand, users clicking through interfaces, transactional databases recording every sale. The environment is the agent's world.
Perceives: the agent gathers information through sensors, telemetry, cameras, microphones, logs, or any input mechanism. This is how the agent ingests signals from the world. It's listening, watching, reading.
Acts: the agent intervenes in its environment—it executes commands, generates outputs, sends messages, moves actuators, issues control signals. This is how it pushes back on the world. Perception is input; action is output.
Maximizes chances of success: the agent makes decisions that optimize toward a specified objective. Intelligence, in this operational sense, is the discipline with which actions are chosen against goals.
There's no requirement for consciousness. No requirement for self-awareness. No requirement for emotion. There's no mention of machines "understanding" in the human sense. The bar is defined operationally: does the system, given its inputs, select actions that maximize its chances of achieving a clearly specified goal?
You don't need metaphysics to work effectively with AI. What matters is clear objectives, observable environments, and agents that can be evaluated against them.
The Reality Check: Strong AI Versus Narrow AI¶
The distinction between Strong AI and Narrow AI is the single largest source of confusion in the field. The industry is drowning in hype about "AGI"—a term that appears in press releases, investor decks, and Twitter threads with religious frequency. Clear thinking about this distinction determines whether you make sound decisions or let narratives serving someone else's interests take over.
Strong AI (Artificial General Intelligence)¶
AGI refers to hypothetical systems possessing human-level intelligence across all cognitive domains. Such a system would learn any intellectual task a human can perform. It would transfer that learning fluidly between arbitrary domains—from chess to poetry to medical diagnosis to mechanical engineering. It would reason with common sense. And it would do all of this without task-specific retraining.
Status as of January 2026: AGI doesn't exist. The number of verified, deployed AGI systems in operation is zero.
Timeline estimates for achieving AGI range from five years to fifty years to never, depending on whom you ask. Companies have strong incentives to label their products as "AGI" because the term attracts attention and investment. In late 2025, several AI companies publicly claimed to have achieved "AGI-capable" status—a pattern that MIT Technology Review, in October 2025, described as "the most consequential conspiracy theory of our time." Without precise definitions and agreed-upon benchmarks, these claims are mostly rhetorical.
The ARC-AGI Benchmark Reality Check: François Chollet, an AI researcher at Google known for creating the deep learning library Keras, designed the ARC-AGI benchmark to test abstract reasoning—visual puzzles that are easy for humans but difficult for AI. The tasks look simple: colored grids with patterns that must be extended or transformed according to rules implied by examples. A child can often solve them in seconds. Until recently, the best AI systems struggled.
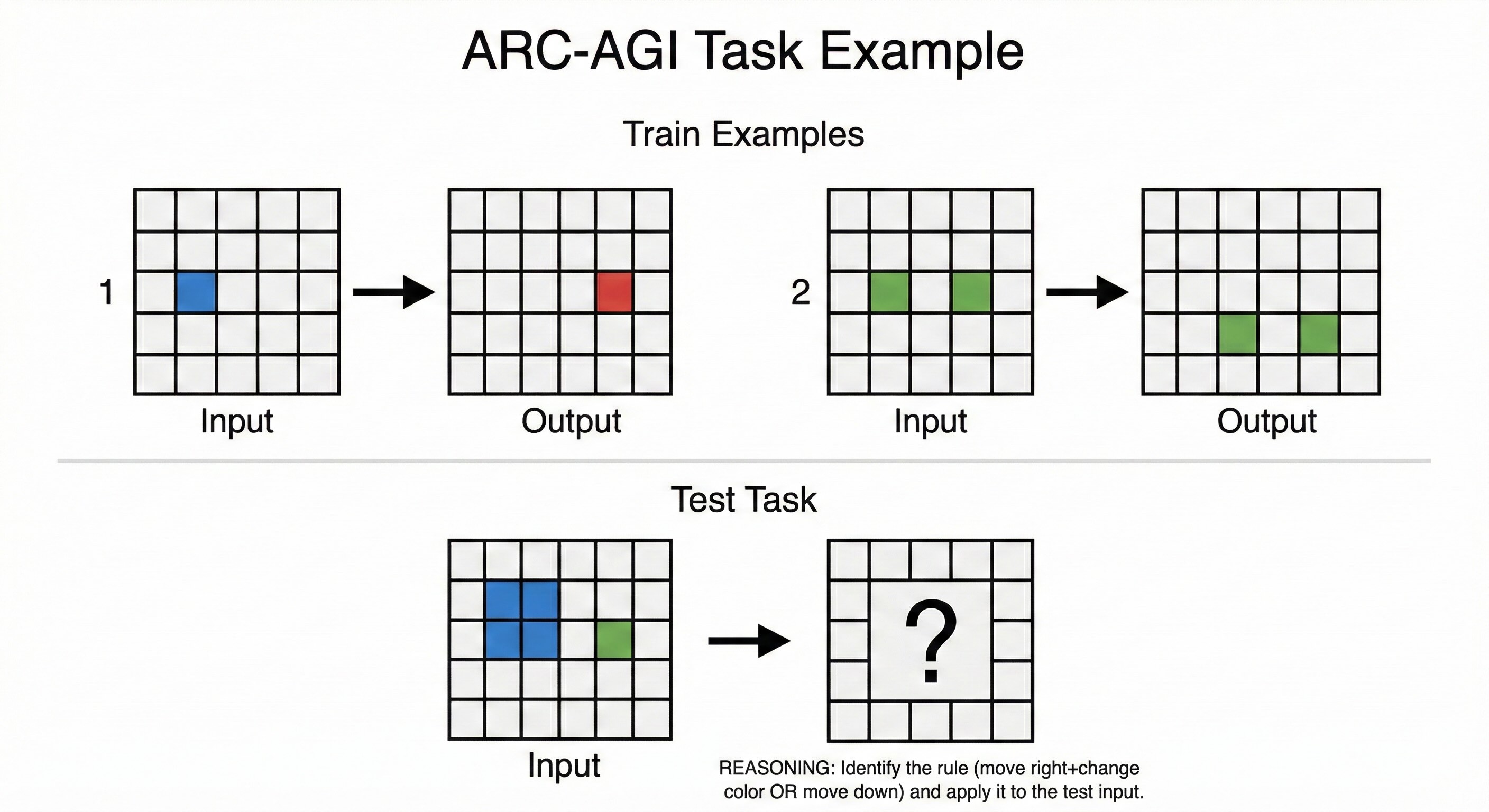
Two versions now exist: ARC-AGI-1, the original benchmark, and ARC-AGI-2, launched March 24, 2025, designed specifically to challenge frontier reasoning systems after models began saturating ARC-AGI-1.
ARC-AGI-1 Progress: GPT-5.2 has achieved 90.5% accuracy on the original ARC-AGI-1 benchmark—the first model to cross the 90% threshold and a milestone that seemed years away in early 2025. This represents genuine capability advancement on tasks that pure LLMs couldn't solve at all in 2023.
ARC-AGI-2 Status (the harder benchmark): As of January 2026, frontier AI models have made material progress on ARC-AGI-2: GPT-5.2 Pro (High) leads among base models at 54.2% ($15.72/task), with GPT-5.2 Thinking achieving 52.9%. The most significant breakthrough came from Poetiq's refinement approach: their GPT-5.2X-High configuration achieved 75% at under $8/task (announced January 14, 2026)—exceeding the average human performance of 60%. Gemini 3 Pro achieves 31% baseline ($0.81/task), but Poetiq's refinement solution on Gemini 3 Pro reaches 54.0% at ~$31/task, demonstrating that "model refinement loops" can significantly boost performance without new model architectures. The ARC Prize team has characterized 2025 as the "Year of the Refinement Loop," noting that progress is increasingly being driven by systems that verify and refine outputs at the application layer rather than raw model training.
For reference, calibrated human panel performance on ARC-AGI-2 approaches 85-100% depending on the evaluation set, while crowdsourced MTurk-style participants average 60-77%. The wide range reflects how task motivation and domain expertise affect human performance—a reminder that "human-level" is itself a distribution, not a fixed point. The Poetiq result suggests that with the right inference-time techniques, AI can now exceed average human performance on this benchmark—though the gap to expert-level human performance persists on tasks requiring genuine novel abstract reasoning.
Looking Ahead: ARC-AGI-3 is in developer preview (released mid-2025) with full launch planned for 2026. Unlike previous versions, ARC-AGI-3 is the first interactive reasoning benchmark—testing AI systems on game-like environments that require real-time adaptation rather than static puzzle-solving. Early results suggest current models score literally 0% on these interactive tasks, indicating that despite progress on ARC-AGI-2, substantial capability gaps remain for truly adaptive reasoning.
A Note on Benchmark Integrity: As model performance on ARC-AGI-2 has improved, concerns about benchmark contamination have emerged. Some researchers worry that as benchmarks become widely known, models may be inadvertently or deliberately trained on test data, inflating scores without genuine capability improvement. The ARC Prize Foundation addresses this by maintaining semi-private evaluation sets distinct from public training data, but the tension between benchmark visibility and evaluation integrity remains an ongoing challenge in the field. This is one reason why ARC-AGI-3's interactive format—which requires real-time novel problem-solving rather than pattern-matching on known task formats—represents an important evolution in AGI measurement.
Narrow AI (Weak AI)¶
Narrow AI refers to systems specialized for specific tasks. These systems can vastly exceed human performance within their domain—chess, protein folding, medical X-ray classification, fraud detection, code generation, demand forecasting—but they can't generalize beyond their training distribution without retraining. Move them into a new task or context, and they degrade or fail.
Status as of January 2026: This is what exists and can be deployed. This is what really matters.
The terminology can deceive. "Narrow" doesn't mean "limited value." Almost all of the economic impact of AI today comes from highly specialized systems. A fraud detector that's narrow but accurate can save a bank billions—flagging suspicious transactions before they clear, around the clock, never taking a break. A demand forecaster that's narrow but reliable can reshape an entire supply chain—adjusting inventory levels before shortages materialize. A portfolio of well-chosen narrow agents can transform an organization. Breadth isn't a prerequisite for impact. Specialization is where the current leverage lies.
The Two Engines: Symbolic AI and Connectionism¶
Understanding AI requires grasping the two fundamental paradigms for building intelligent systems—two different engines that can power the same car. Both can construct rational agents. Both come with sharp trade-offs you need to understand before making architectural decisions.
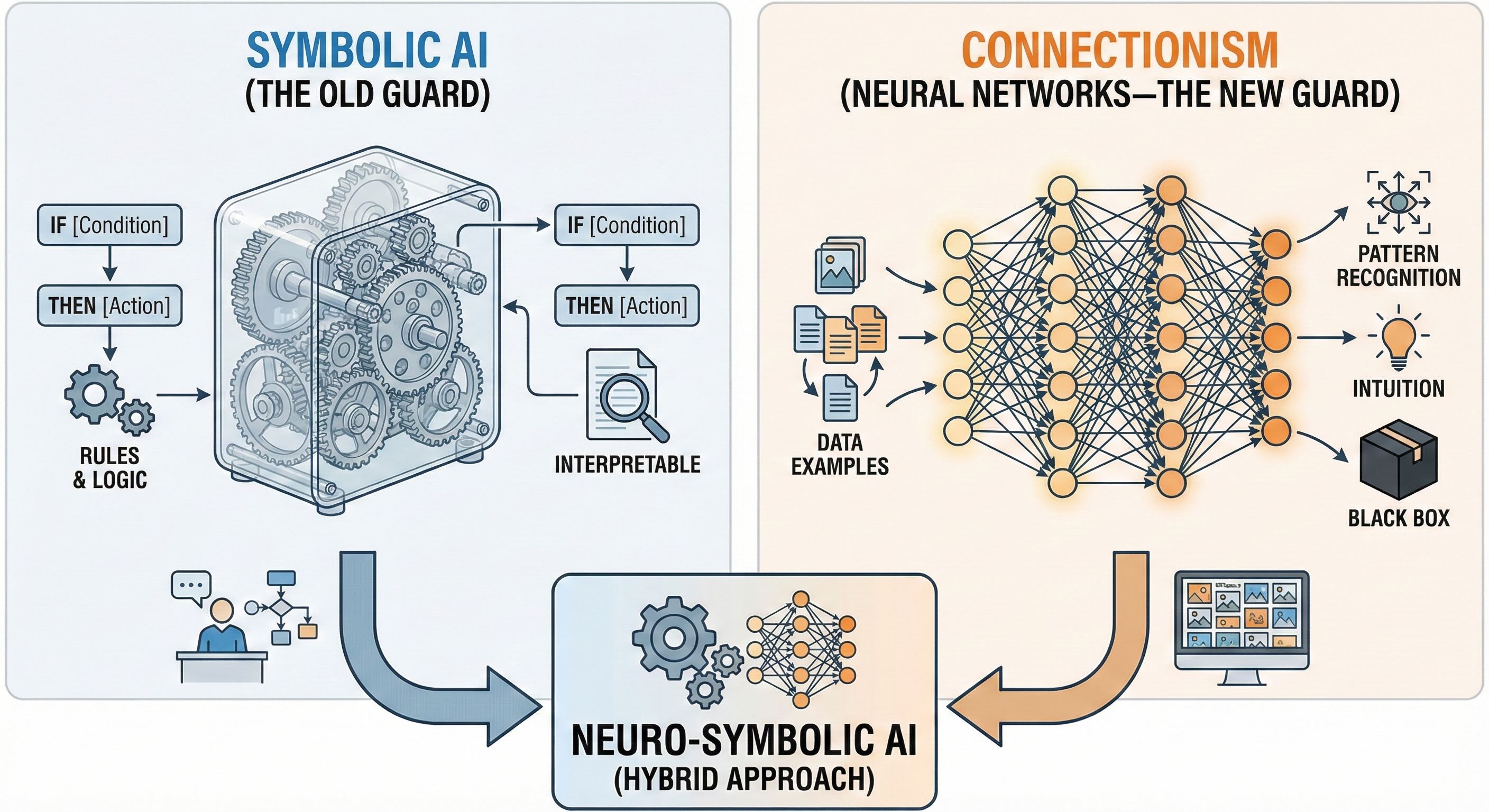
Symbolic AI (The Old Guard)¶
In symbolic AI, knowledge is represented explicitly through symbols, rules, and formal logic. Expert systems, theorem provers, and classical planning systems belong to this tradition.
Picture how it works: a knowledge engineer sits with a domain expert—a tax accountant, a doctor, a loan officer—and painstakingly transcribes their decision process into if-then rules. If the applicant's debt-to-income ratio exceeds 43%, flag for manual review. If the patient presents with chest pain and shortness of breath, order an EKG. The system operates like a legal code: if this condition holds, then take that action; if these constraints are violated, flag an exception.
Strengths: Symbolic systems are interpretable. When the rules are correct and complete, you can trace the reasoning exactly. Decisions can be inspected, audited, and verified for correctness. In regulated domains—banks, hospitals, nuclear facilities—in safety-critical settings, this interpretability is often a requirement. You can show a regulator exactly what the system is doing and why.
Weaknesses: Symbolic systems are brittle. If the system encounters a situation not covered by its rules, it has nothing to say—or worse, it fails silently, confidently doing the wrong thing. Acquiring and encoding all necessary knowledge is painfully slow. This bottleneck has a name: the knowledge acquisition problem. Writing and maintaining the rule base becomes an organizational chokepoint. Every new situation requires a human expert to encode new rules. It doesn't scale.
Connectionism (Neural Networks—The New Guard)¶
In connectionist systems, knowledge isn't programmed explicitly. It emerges from the weighted connections between interconnected processing units—neurons, in the neural network metaphor.
The approach has roots in the 1940s, when Warren McCulloch and Walter Pitts first proposed mathematical models of neurons. But it languished for decades, dismissed after Marvin Minsky and Seymour Papert's 1969 book Perceptrons catalogued its limitations. The revival came slowly, then suddenly—hardware improvements, new training algorithms, and mountains of data combined to make deep learning the dominant paradigm by the mid-2010s.
These systems function as cultivated intuition. Instead of hand-coding rules, you expose the model to vast quantities of examples and let it learn statistical regularities. Show it millions of labeled images, and it learns to distinguish cats from dogs. Feed it billions of words, and it learns the structure of language. Deep learning is the modern expression of this tradition.
Strengths: Connectionist systems learn directly from data—you don't have to program the knowledge; you show examples and let them figure out patterns. They handle high-dimensional, noisy inputs remarkably well—photographs, recorded speech, natural language text, telemetry streams from sensors. They tolerate ambiguity, degrade more gracefully when inputs are messy, and discover patterns no human would ever think to program. Patterns that were unknown.
Weaknesses: These systems are black boxes. Understanding why a neural network made a specific decision is often difficult or impossible. Explaining to a regulator why a loan was denied becomes challenging when the honest answer is: "The weights said so." They're data-hungry, requiring massive training datasets to achieve strong performance. And they're vulnerable to adversarial inputs—carefully crafted perturbations that cause confident, catastrophic errors. Researchers have shown that changing a few pixels in an image—invisible to the human eye—can make a system think a stop sign is a speed limit sign. You trade legibility for adaptability.
The Modern Reality: Neuro-Symbolic AI¶
Neither paradigm is sufficient on its own. Contemporary AI increasingly uses hybrid approaches that combine symbolic reasoning with neural computation—a field now formally called Neuro-Symbolic AI, or NeSy. This isn't a niche research topic. This is the convergent direction of the entire field.
A language model proposes actions, but a rule-based layer filters out anything that violates policy. A vision model detects objects, but then a planner reasons symbolically about how to manipulate them. Neural networks handle perception and pattern recognition—what they're good at—while symbolic components enforce business rules, regulatory constraints, or safety checks—what they're good at. The most effective architectures combine statistical strength with explicit control.
The Strategic Reality¶
The mission is deploying rational, narrow agents that solve valuable problems. When someone proposes an "AI solution," pointed questions become essential: Which paradigm are we leaning on, and where? Are we deploying a rational agent with a clear environment and goal definition? Are we relying primarily on symbolic rules, on learned patterns, or on a deliberate blend of the two? Do we need interpretability more than raw performance here, or is the reverse true?
These distinctions aren't academic. They determine what can be deployed in specific industries, how failures are debugged, and whether systems will survive contact with the messy, unpredictable real world. Good questions are reliable risk control.
The goal isn't to become a research scientist. The goal is precision about what you're working with, building, or evaluating. Define AI in operational terms: agents that perceive, act, and optimize toward specified goals. Anchor expectations in narrow, rational systems—that's where real capability lives today. Understand the trade-offs between symbolic clarity and connectionist adaptability, and insist that choices are justified in those terms.
Interpretability is often the price of performance—but that trade-off must be made deliberately, not by accident.
For Further Exploration¶
The foundational concepts in this chapter connect to several advanced frameworks that deepen expertise.
Levels of AGI Framework (Google DeepMind, November 2023)
Rather than treating AGI as a simple threshold—it either exists or it doesn't—DeepMind researchers proposed a taxonomy with six performance levels (Level 0 through Level 5), ranging from "Emerging" (equal to or slightly better than an unskilled human) through "Superhuman" (outperforms 100% of humans). The framework distinguishes between narrow and general capabilities at each level, and separately considers autonomy levels with associated risks. As of January 2026, frontier models like GPT-5.2 and Claude Opus 4.5 arguably reach "Competent" (50th percentile human) on many narrow tasks, but they remain at "Emerging" for truly general capabilities. This nuanced taxonomy is far more useful than the binary Strong/Narrow distinction when evaluating claims and setting realistic expectations.
AI Safety Levels (ASL) Framework (Anthropic)
Relevant for high-stakes deployments. Anthropic's Responsible Scaling Policy defines AI Safety Levels—ASL-1 through ASL-4 and beyond—based on a model's potential for catastrophic misuse. Each level triggers specific safety requirements before training or deployment can proceed. Claude Opus 4.5 was evaluated under this framework before release. Understanding ASL provides a governance vocabulary for risk assessment that goes beyond capability benchmarks, addressing potential for harm rather than just potential for usefulness.
The Bitter Lesson (Rich Sutton, 2019)
A foundational essay that every serious practitioner should read. Sutton, a professor at the University of Alberta and a pioneer of reinforcement learning, argues that the history of AI shows a consistent pattern: general methods leveraging computation—search and learning—ultimately outperform approaches that try to encode human knowledge. This perspective helps explain why connectionist approaches have dominated and why scale has been such a powerful lever. The efficiency revolution of 2025 with DeepSeek and Phi-4 suggests the lesson may be evolving. Perhaps it's not just "computation wins" but "computation efficiency wins."
Constitutional AI and RLHF
The alignment techniques underlying modern reasoning models. Reinforcement Learning from Human Feedback (RLHF) and Constitutional AI represent practical implementations of that "uncertain objectives" principle from Russell and Norvig's 4th edition—addressing how to build systems that optimize for what humans actually want when that isn't entirely certain. These methods are covered in depth in Part 8 (Advanced LLM) and Part 15 (Governance and Ethics).