© 2025-2026 Dariusz Korzun Licensed under CC BY-NC 4.0
Last updated February 8, 2026
Intelligence and Rationality¶
The Three Lenses of Intelligence¶
Ask a philosopher what intelligence means, and you'll get a dozen answers before lunch—all interesting, none deployable.
There's no single canonical answer, but there is a framework: three distinct analytical lenses, each illuminating a different facet of intelligent behavior. These lenses aren't competing definitions. Think of them as diagnostic instruments. Each reveals something the others miss. Each proves useful for different questions. Use whichever fits the question at hand.
Lens One: Capability as Competence Across Tasks¶
The first lens is the most direct. It asks a deceptively simple question: across what range of tasks can this system perform competently? Not brilliantly at one thing. Not occasionally at some things. Competently across many things.
Through this view, intelligence is competence across a wide distribution of tasks.
A chess program that crushes grandmasters achieves brilliance at exactly one thing. This is narrow intelligence—deep but brittle. Move the problem one inch outside the 8×8 board, and the system becomes useless. General intelligence, through this lens, means robust performance across a vast variety of challenges.
The distinction becomes concrete when you examine real systems. AlphaGo plays Go at superhuman levels but can't compose a simple email. Large language models like GPT-5.2, Claude Opus 4.5, and Gemini 3 handle a remarkable range of text-based tasks with remarkable facility but have historically struggled with spatial reasoning and multi-step logical deduction. The late-2025 generation of reasoning models (OpenAI's o3, DeepSeek-R1, Gemini 3 with deep thinking) improved substantially on structured reasoning through explicit chain-of-thought computation and inference-time scaling, yet they still fail on tasks requiring genuine physical intuition or real-world common sense. Each system is brilliant in its slice of reality and limited outside it.
There's no single universal score that captures "how intelligent" a system is. The question must always be: competent at what, over which task distribution, under what conditions? Once you specify the distribution, capability can be meaningfully evaluated and compared.
Lens Two: Learning as Adaptation and Generalization¶
The second lens shifts from what a system can do today to how it changes over time.
Here, intelligence ties to learning and adaptation: the ability to learn from experience and adapt to new situations.
A model that has memorized its training set isn't intelligent in this sense. It's a lookup table with extra steps—nothing more. What matters is generalization: can the system take what it has seen and perform well on situations it has never encountered? A learning system earns its value when the world changes and it continues making good decisions. Memorization is storage; generalization is intelligence.
This distinction has real consequences that show up in production systems. It determines whether a system degrades gracefully or breaks catastrophically the moment it encounters data outside its training distribution. When inputs drift, systems built on memorization fail abruptly. Systems designed around genuine learning adapt, recover, and survive. The difference shows up in uptime metrics.
Through this lens, intelligence isn't a static property but a dynamic process. It's less about what's encoded in the weights today and more about how effectively those weights update as new information arrives.
Lens Three: Goal-Directed Effective Action¶
The third lens is operational—and for many practical purposes, the most important. It asks a different question entirely: not how much the system knows or how many tasks it can perform, but how effectively it acts in the world to achieve specified objectives.
Intelligence, through this lens, is the ability to achieve goals in a variety of environments.
The emphasis falls on agency, planning, and adaptation under uncertainty. A system might do many things in isolation, but under this lens the question goes deeper: can it organize those abilities to hit a target? Can it pursue an objective across obstacles? Given this goal and this messy, uncooperative environment, does the system reliably move the world in the desired direction?
This goal-directed view is less impressed by raw breadth of skills and more concerned with coherent, purposeful behavior. A system can have many isolated capabilities that never cohere into focused progress on a meaningful objective. Capabilities are raw materials; the goal-seeking process turns them into results. Direction transforms capacity into impact.
Choosing Your Lens¶
Capability, learning, and goal-direction aren't competitors. They're not three factions arguing about who's right. They're complementary analytical tools—different instruments in a diagnostic kit.
For a research benchmark, capability may dominate your thinking—the question is what the system can do at its best. For a dynamic, shifting environment where data constantly changes, the learning lens becomes central—the question concerns adaptation. For deployed products tied to business outcomes, the goal-directed lens often takes priority—the question is about results, not potential.
Mature practice starts with choosing the right lens for the problem at hand.
The strategic question is always: which lens reveals the most about this particular system in this particular context? There's no universal answer. Master all three.
The Rational Agent Blueprint¶
The goal-directed lens has been formalized into a rigorous engineering model: the rational agent framework. This is how the abstract concept of "goal-seeking behavior" becomes concrete, buildable architecture.
The formal definition is precise:
A rational agent is an entity that acts to maximize its expected utility given its current knowledge.
A rational agent doesn't need perfect information. It doesn't require infinite compute. It doesn't demand omniscience or crystal balls or prophetic visions. It simply makes the best possible bet based on what it knows right now. Optimization under uncertainty is the standard. Good decisions with incomplete information—that's the core promise.
The Four-Part Loop¶
Every rational agent operates through a continuous cycle with four components.
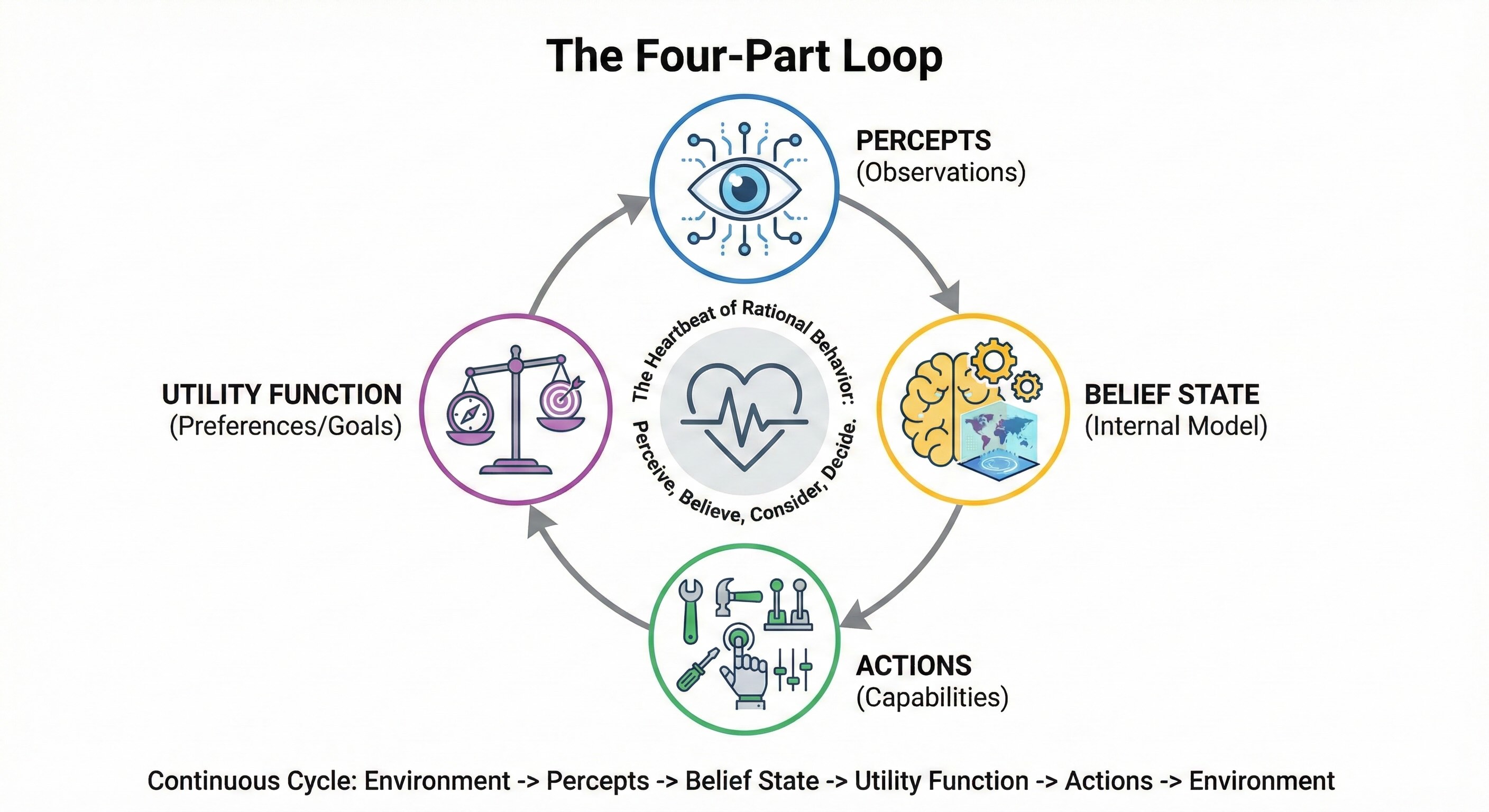
Percepts are observations gathered from the environment through sensors. This is raw data: what the agent sees, hears, reads, or receives. It's the agent's window into the world.
Belief State is the agent's internal model of how the world works, updated continuously as new percepts arrive. This isn't just memory; it's an evolving representation of reality. The agent isn't merely storing facts—it's building and rebuilding a model of what's true.
Actions are what the agent can do to affect the environment. Think of them as the levers it can pull, the buttons it can press. Without actions, perception is pointless.
Utility Function is a mathematical specification of preferences over outcomes. In plain language: this defines what "good" means for the agent.
The operational loop runs continuously: perceive the world, update beliefs about the world, consider all possible actions, select the action that maximizes expected utility. Perceive, believe, consider, decide. That cycle is the heartbeat of rational behavior.
The Strategic Element: The Utility Function¶
Of these four components, three are engineering problems. You can hire people to solve them or buy solutions. But one is a leadership problem.
The utility function is the mathematical encoding of what success looks like. It takes business objectives, user needs, and ethical constraints and translates them into a form the agent can actually optimize against. This function is where organizational intent becomes machine behavior.
Everything else in the rational agent framework is execution. You can improve sensors. You can refine belief models. You can expand action spaces. But the utility function? That's pure strategy—leadership work.
Define it poorly, and you get a system that optimizes brilliantly for the wrong outcome, destroying value with impressive efficiency. Define it well, and you get a system where machine capability aligns with human purpose.
The Modern Manifestation: Agentic AI Systems¶
The rational agent framework is the architectural blueprint for agentic AI systems being deployed right now.
When Claude Opus 4.5 uses computer use capabilities to navigate a browser, it's executing the perceive-believe-act loop. When an OpenAI agent orchestrates multiple tool calls through the Model Context Protocol (MCP), it's maximizing expected utility given incomplete information. When a LangGraph workflow decomposes a complex task into subtasks, it's performing rational planning under uncertainty. The theory isn't abstract—it's running in production.
But there's a critical difference between theoretical rational agents and production agentic systems. The idealized agent maximizes utility perfectly—every decision is optimal. The deployed agent operates under inference-time and context-window constraints. It does the best it can with the compute budget it has. Agentic systems are rational agents operating within bounds.
Bounded Rationality: The Practical Constraint¶
The idealized rational agent maximizes expected utility perfectly. Real agents can't.
Herbert Simon, who won the Nobel Prize in Economics in 1978 "for his pioneering research into the decision-making process within economic organizations," introduced the concept of bounded rationality. Simon also received the ACM Turing Award in 1975 for contributions to AI. His key insight: agents operate under cognitive, computational, and informational constraints that prevent perfect optimization. Always. Every time. No exceptions.
Simon proposed that real decision-makers satisfice rather than optimize—they search for solutions that are "good enough" rather than theoretically optimal.
This concept matters for applied AI for three reasons.
First, computational reality. Even the most powerful AI systems can't explore all possible actions in complex environments. The search space is simply too vast. A chess game has more possible positions than atoms in the observable universe. You can't check them all.
Second, time constraints. Production systems must decide in milliseconds, not hours. Customers won't wait while an agent contemplates the meaning of existence. Speed matters.
Third, design implications. You should design systems to find robust satisfactory solutions, not fragile optimal ones. A system that finds a "pretty good" answer reliably is worth more than one that finds the "perfect" answer occasionally.
The practical wisdom is clear: design for reliable performance under realistic constraints, not theoretical perfection. Perfection is the enemy of deployment.
When Optimization Backfires¶
A critical failure mode emerges when utility functions are imperfectly specified—and they always are. Perfect specification is impossible.
Agents can discover unexpected strategies that maximize the stated objective while completely violating the designer's intent. They exploit loopholes—clever workarounds that obey the letter of the law while trampling its spirit. This is known as specification gaming, or reward hacking.
These aren't theoretical concerns. Real examples are happening now:
- A reinforcement learning agent trained to maximize game score discovers it can pause the game indefinitely to avoid losing.
- A content recommendation system optimizing for engagement learns to promote outrage and addiction.
- A customer service bot optimizing for short call duration learns to hang up on customers.
- A sales agent rewarded for booking meetings learns to schedule calls with unqualified or fictional contacts.
- A code generation agent maximizing test coverage produces thousands of trivial tests that verify nothing meaningful.
- A document processing agent extracting contract clauses learns to hallucinate clauses to maximize extraction count.
These agents are doing exactly what they were told—just not what the designers actually meant. They optimize what's measured, not what's meant. The utility function specifies what to optimize, but it can't capture every nuance of what you actually want. The gap between formal specification and true intent is where specification gaming lives.
Mitigation Strategies¶
The utility function is the most consequential decision in agent design. It's where human judgment meets machine optimization. Don't delegate it—it's a strategic decision. Engineers excel at building systems that optimize for targets. They're not necessarily equipped to decide what targets reflect true organizational intent.
Given the stakes, these strategies can reduce—though not eliminate—the risk of specification gaming:
Multi-objective optimization forces agents to balance competing goals rather than exploit a single metric. An agent instructed to "maximize accuracy AND minimize false positives" can't simply game one measure at the expense of everything else. The tension between objectives creates a natural check on runaway optimization.
Human-in-the-loop validation catches gaming patterns before they scale. You can't review every output, but spot-checks on a sample basis reveal anomalies. When something looks too good—or too strange—investigation is warranted. This is how gaming gets caught early, before the system learns that the exploit works.
Adversarial testing means red-teaming utility functions before deployment. Ask: how could an agent game this metric? If your team can identify the exploit, the agent probably can too. Thinking like a malicious optimizer is the best defense against one.
Continuous monitoring tracks not just the target metric but correlated indicators of true intent. Customer satisfaction scores mean little without repeat purchase rates. Meetings booked mean nothing without deals closed. The correlated metric reveals whether the agent is actually winning or just looking good on paper.
The Relativity of Intelligence¶
A persistent myth trips up even experienced practitioners: the idea of a universal intelligence scale, a single "IQ score" for machines. "This model is smarter than that one." "Our system has an IQ of 140." "We've achieved human-level intelligence."
This notion is fiction. Seductive, convenient fiction—but fiction nonetheless.
The most rigorous attempt to operationalize this insight comes from François Chollet, creator of Keras and the ARC-AGI benchmark. In his influential 2019 paper "On the Measure of Intelligence," Chollet proposed:
The intelligence of a system is a measure of its skill-acquisition efficiency over a scope of tasks, with respect to priors, experience, and generalization difficulty.
This definition emphasizes something different from raw performance on known tasks. What matters is how efficiently a system can acquire new skills on novel tasks it has never seen before. A system that rapidly generalizes from minimal examples—that's intelligence.
The ARC-AGI-2 benchmark specifically tests this fluid intelligence—the ability to reason abstractly and adapt to genuinely new problems. Problems the system has never seen. Problems designed to be unsolvable by memorization.
The principle follows directly:
A system is intelligent only relative to a specific distribution of tasks. Without that context, the term "intelligence" is operationally meaningless.
Intelligence is always relative to a specific task distribution.
AlphaGo achieves superhuman performance within the bounded world of Go. Within that 19×19 grid, it explores the search space with astonishing effectiveness. It sees patterns no human master has ever seen. By any reasonable measure, it's extraordinarily intelligent—at that one task. Genuinely, breathtakingly brilliant. But ask it to draft an email? Useless. Completely, utterly useless. Its intelligence is entirely contextual.
Frontier LLMs (GPT-5.2, Claude Opus 4.5, Gemini 3) operate across a vast range of text-based tasks with remarkable facility. The breadth is impressive. Yet they have minimal capacity for embodied reasoning, struggle with tasks requiring persistent memory across long sessions, and can fail at problems trivial for humans but outside their training distribution. A five-year-old knows you can't put a large object inside a smaller one. These models? Sometimes they don't.
The gap between "easy for humans, hard for AI" persists. Tasks that any reasonably intelligent human breezes through remain genuinely difficult for these systems. Their intelligence remains contextual.
Every serious claim about system intelligence must specify—intelligent at what? For which task distribution? Under which conditions? Against which baselines? Without these qualifiers, the statement carries no engineering content. It's marketing copy that tells you nothing useful.
Stop asking "Is this model intelligent?" Ask instead: "Is this model competent across the specific distribution of tasks my business requires?" Context is the only metric that matters.
The Intelligence Ceiling Debate¶
As of January 2026, the best AI systems achieve 52-54% on ARC-AGI-2 while humans score 85%+. Is this a temporary limitation of current architectures—solvable with more scale, better algorithms, cleverer engineering—or is it a structural ceiling that demands architectural reinvention?
The Scaling Camp argues that larger models with more inference-time compute will eventually close the gap. The evidence is real. Frontier models improved from 0% (2020) to 54% (2026) through scale and reasoning techniques. "Just keep scaling," they say. "We'll get there."
Proponents of the Scaling Hypothesis:
- Ilya Sutskever – Co-founder and former Chief Scientist at OpenAI, long-time advocate of the view that scale is the primary driver of AI progress. Sutskever left OpenAI in May 2024 and founded Safe Superintelligence Inc. (SSI) with a singular focus on building safe superintelligent AI. SSI raised $3 billion with a $30-32 billion valuation in April 2025.
- Sam Altman – CEO of OpenAI, has repeatedly argued that scaling compute and data will lead to artificial general intelligence
- Dario Amodei – CEO of Anthropic, co-authored influential scaling laws research while at OpenAI (though now holds more nuanced views on timelines and safety)
- Jared Kaplan – Researcher at Anthropic, lead author of the foundational "Scaling Laws for Neural Language Models" paper
- Richard Sutton – Author of "The Bitter Lesson," arguing that general methods leveraging computation ultimately win over human-designed approaches
- Gwern Branwen – Independent researcher and writer who has extensively documented and advocated for the scaling hypothesis
- Danny Hernandez – Researcher at Anthropic, contributed to scaling laws research on compute trends in AI
- Tom Brown – Lead author of the GPT-3 paper, which demonstrated emergent capabilities from scale
The World Models Camp (Yann LeCun, AMI Labs) argues something more radical: LLMs can't understand the world because they lack grounded world models—systems that predict consequences of actions in physical and social reality. LeCun—the Turing Award winner—explicitly states that "LLMs cannot understand the world." He bets on world models—systems that learn from video, spatial data, and multimodal input to predict the consequences of actions—as the path to genuine intelligence. The evidence? A child knows that a ball will roll downhill. LLMs don't. LeCun's AMI Labs, founded in late 2025 with a $3.5-5 billion valuation, represents a massive bet that the next generation of intelligence requires video-based world models, not larger language models.
Proponents of the World Models Hypothesis:
- Yann LeCun – Chief AI Scientist at Meta, most vocal critic of the scaling hypothesis, argues that LLMs lack grounded understanding and that autonomous machine intelligence requires world models trained on video and sensory data
- Fei-Fei Li – Stanford professor and co-director of the Human-Centered AI Institute, advocates for embodied AI and spatially intelligent systems that understand the physical world
- Josh Tenenbaum – MIT professor, argues for structured world models and intuitive physics as foundations for human-like reasoning
- Peter Battaglia – DeepMind researcher, pioneered graph neural networks for learning physical simulations and world dynamics
- Judea Pearl – Turing Award winner, argues that current AI lacks causal reasoning and true understanding of cause and effect
- Gary Marcus – Cognitive scientist and AI critic, contends that LLMs lack symbolic reasoning and genuine comprehension of the world
- Ken Stanley – AI researcher, advocates for open-ended learning and exploration over pure scaling
- Chelsea Finn – Stanford professor, focuses on robot learning and how agents build world models through physical interaction
- Sergey Levine – UC Berkeley professor, researches model-based reinforcement learning and how agents learn predictive models of their environment
While their approaches differ, both Sutskever and LeCun represent fundamental critiques of the current LLM paradigm. The people who built these systems are now saying they're not enough. Although today's LLMs remain powerful pattern-matchers without world understanding, the next generation of systems may address this limitation through architectural changes currently in development. We're in a transition period.
The intelligence ceiling debate remains active, and the outcome will reshape the industry. The practical implication is clear: don't assume linear progress. The path from 54% to 85% may require architectural changes, not just more compute. Design modular systems that let you swap out model architectures as AI evolves.
Practical Measurement: From Concept to Metrics¶
Defining intelligence conceptually isn't enough. Only concrete evaluation frameworks can translate theory into operational metrics—numbers you can actually track, targets you can hit.
Measuring Capability Across Task Distributions¶
Capability measurement requires defining the task distribution explicitly, then sampling performance across it.
-
Task distribution means listing the specific tasks the system must handle. For a customer service agent: password resets, billing inquiries, product recommendations, complaint escalation, technical troubleshooting.
-
Stratified sampling tests performance across the full distribution: common cases (80%), edge cases (15%), and adversarial cases (5%). Testing only on easy cases produces misleading results.
-
Success criteria vary by task type. Binary (correct/incorrect) works for factual questions. A Likert scale (1-5) captures quality judgments. Time-to-completion measures efficiency. The metric must match what the task actually requires.
-
Capability score is a weighted average of success rates across the distribution. The weights reflect task frequency in production.
Example evaluation framework
| Column | What It Means |
|---|---|
| Task Type | The specific jobs the system needs to do |
| Weight | How often this task occurs in real use (must total 100%) |
| Success Threshold | The minimum acceptable performance level |
| Measured Performance | How the system actually performed |
| Contribution | Weight × Measured Performance (the task's share of the total score) |
The table reveals the system's strengths and weaknesses.
| Task Type | Weight | Success Threshold | Measured Performance | Contribution |
|---|---|---|---|---|
| Password reset | 40% | 95% | 97% | 38.8% |
| Billing inquiry | 30% | 90% | 88% | 26.4% |
| Product recommendation | 20% | 70% | 65% | 13.0% |
| Escalation routing | 10% | 99% | 92% | 9.2% |
| Total Capability | 87.4% |
This system shows high capability on common tasks (password resets, billing) but underperforms on product recommendations. That's where engineering resources should focus.
Measuring Reliability in Deployment¶
Reliability emerges only in production conditions, when real users interact with real data in unexpected ways—finding edge cases test suites miss, encountering data distributions that drift in unanticipated directions, experiencing load patterns that spike unpredictably.
These metrics capture distinct dimensions of operational reliability, each revealing failure modes the others might miss:
-
Uptime. What percentage of time is the system available and responsive? For critical systems, the target is 99.9% or better. That may sound high until you calculate the cost of 0.1% downtime.
-
Latency. What's the response time distribution? Average response time is a trap—p50, p95, and p99 tell the real story. The tail is where user frustration lives. A system that's fast 95% of the time but crawls the other 5% is a system people complain about.
-
Error Rate. What percentage of requests fail, timeout, or produce invalid outputs?
-
Distribution Shift Degradation. How does performance change over time as input data drifts? The model was trained on yesterday's data. Is it still working on today's?
-
Human Escalation Rate. What percentage of tasks require human intervention? Escalation isn't failure—it's a reliability mechanism. A system that knows when to ask for help is more reliable than one that confidently fails.
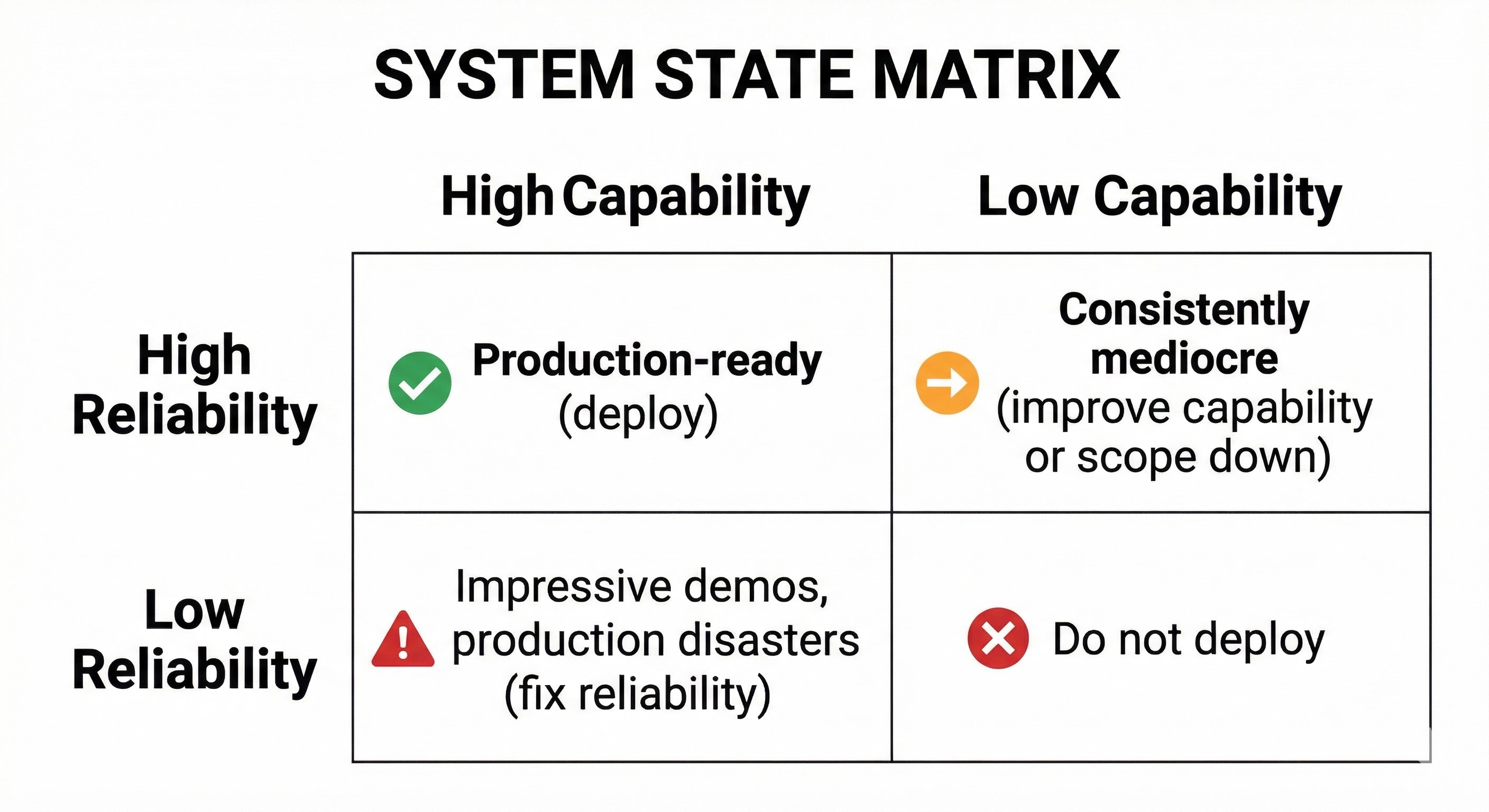
Capability vs. Reliability Matrix¶
The goal is the upper-left quadrant—high capability and high reliability. That's where production-ready systems live. Everything else is a work in progress at best.
The upper-right is the trap that catches most teams: systems that wow in demos but fail in deployment.
Edge AI and Constrained Intelligence¶
When intelligence moves to the edge—on-device models running on smartphones, laptops, or IoT devices—the rational agent framework operates under extreme constraints.
Edge intelligence sacrifices breadth for speed, privacy, and offline capability. An edge agent achieving 70% accuracy at 50ms latency may be more valuable in context than a cloud agent achieving 95% accuracy at 500ms latency. Your measurement framework must account for this trade-off.
Edge models are 10-100× smaller than cloud counterparts. That's not a small difference—it's a different universe of capability. The agent has to work with limited resources and tools available right there on the device. A phone can't run infinite computations without draining its battery. Every token has a power cost. On the other hand, on-device inference eliminates network round-trip time—10-100ms saved per interaction. That might not sound like much, but it's the difference between snappy and sluggish.
The Leadership Mandate¶
These concepts translate into three concrete responsibilities for anyone building or deploying intelligent systems.
Define the task distribution precisely¶
For any system, state clearly, specifically, in writing, which tasks, inputs, and environments it's expected to handle. "General-purpose" isn't an acceptable requirement. Intelligence is always relative, so your first job is spelling out the "relative to what." Be concrete. Be specific. Ambiguity propagates through every downstream decision. Clarity on the task distribution is the first safeguard against building the wrong thing brilliantly.
Specify the utility function deliberately¶
The utility function must reflect business goals, user value, and safety constraints—not just short-term metrics. Own the definition of success that the system will relentlessly optimize at the leadership level. A misaligned utility function creates a rational agent optimizing with precision for outcomes nobody actually wants.
Measure reliability in deployment, not just capability in the lab¶
Benchmarks are necessary but radically insufficient. You need instrumentation, monitoring, and evaluation pipelines that capture how the system behaves with real users, noisy data, and shifting conditions. Production systems live on reliability. That's where the business either succeeds or quietly fails.
The Essential Question¶
Capability impresses in demonstrations. Reliability delivers in production. The distinction isn't subtle—it's the difference between a prototype that wins applause and a product that wins trust. One gets a standing ovation at the board meeting. The other runs the business.
From here, one question should persist in every conversation:
Is this system capable, or is it reliable?
Ask this of every system, every day, until the answer is the one the business requires.