© 2025-2026 Dariusz Korzun Licensed under CC BY-NC 4.0
Last updated February 8, 2026
From Oracle AI to Agentic AI¶
The Pivot from Knowing to Doing¶
The transition happening now may be the most consequential shift in the history of applied AI.
For the better part of a decade, intelligent systems functioned as vast, static repositories of knowledge—oracles capable of dispensing wisdom but incapable of acting on it. These systems could know everything, yet do nothing. That era is ending.
The industry is rotating on a single axis: from knowing to doing. AI is moving away from its role as a passive reference tool and toward something different—an active, autonomous participant in the workforce.
This isn't an incremental upgrade in user interface or model size. It's a fundamental redefinition of the machine's purpose.
Under the oracle paradigm, AI lived primarily in analytics, research, and decision support—essentially a smarter search box, waiting for a query. Under the agentic paradigm, AI moves into execution, operations, and delivery. The boundary between "who decides" and "who acts" is being renegotiated in real time.
The Oracle Paradigm: The Perfect Librarian¶
Oracle AI is defined by its reactive nature. A system designed exclusively for question-answering operates on a strictly linear, passive loop: a user provides input, the AI provides a response. That single arrow captures the entire design philosophy. The interaction is single-turn. The system waits for input, generates output, then returns to dormancy. Search engines operate this way. Traditional chatbots operate this way. Enterprise question-answering systems operate this way. The oracle knows a great deal, but it does nothing with that knowledge unless explicitly commanded.
Picture a reference librarian behind a wooden desk in a university library. A patron approaches and requests a specific book on quantum mechanics. The librarian retrieves that exact book and places it on the counter. She doesn't recommend a superior alternative. She doesn't flag a dated reference. She doesn't volunteer to summarize the first chapter for a board presentation. She doesn't walk to the periodicals section to cross-reference related articles. She fulfills exactly what was requested—nothing more, nothing less. If the patron stops asking questions, the librarian stops providing value. The oracle has zero initiative.
Operationally, oracle AI runs a single short loop: user asks, AI responds, interaction ends. Each exchange begins and terminates in one turn. There's no multi-step plan, no follow-up action, no sense of a larger workflow unfolding over time. The strength of this pattern is predictability. The weakness: nothing moves unless a human pushes.
The limitation is structural, not cosmetic. A system that can't initiate action, can't formulate a goal and pursue it, can't decompose a complex objective into sub-tasks, and can't manage tools on its own—that system will always remain an advisor on the sidelines. This inability to act is the fundamental constraint that agentic AI was engineered to overcome.
The Agentic Paradigm: The Research Assistant¶
Agentic AI inverts the oracle contract entirely. The architecture isn't built around answering—it's built around accomplishing. Instead of waiting passively for a question, an agent receives a goal, an environment, and a set of tools, and moves that goal forward. The measure of success is no longer how well it responded to a prompt, but what actually changed in the world because it existed.
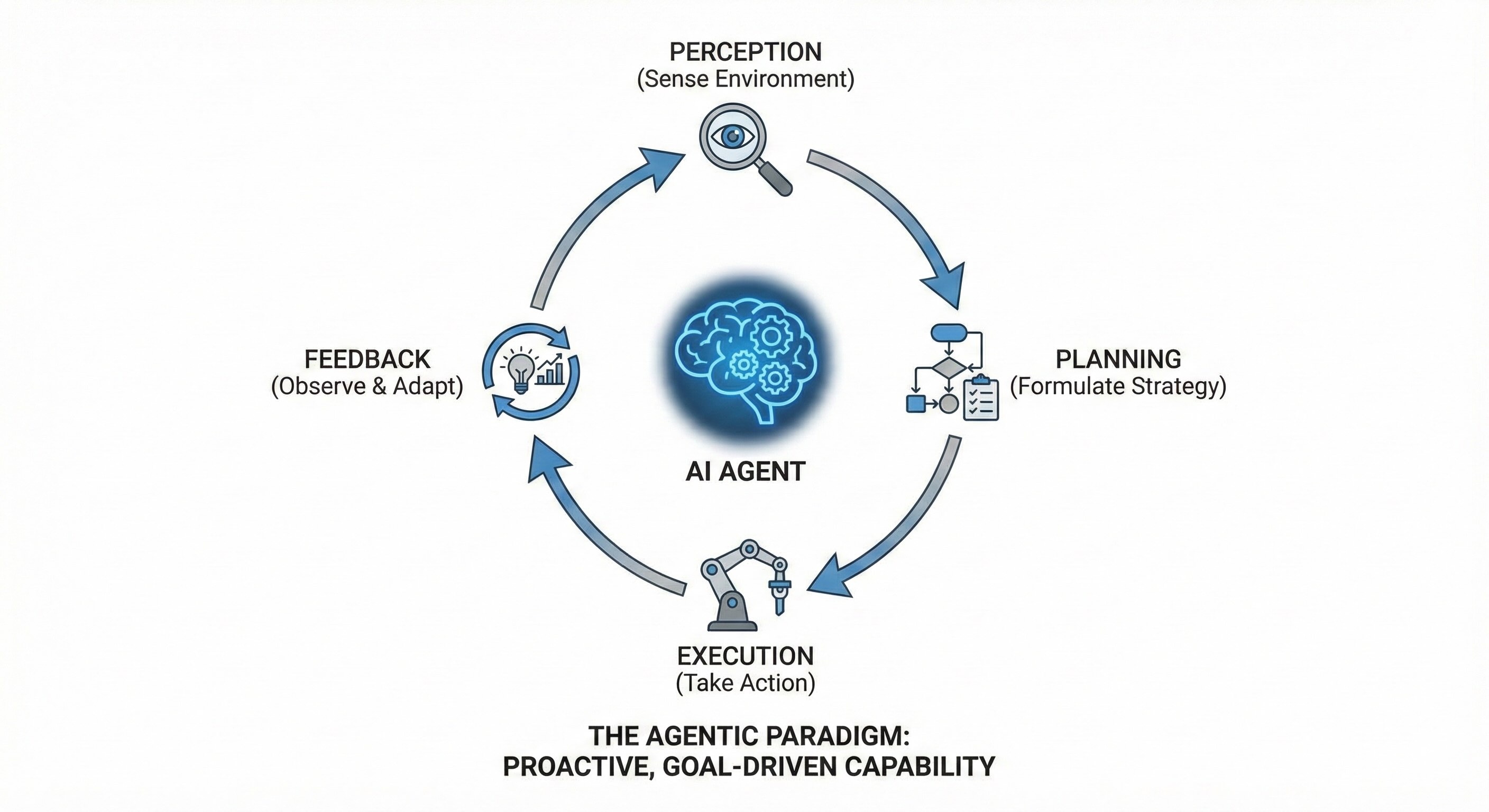
An AI agent operates on a continuous four-step cognitive loop that mirrors biological problem-solving:
-
Perception. The agent actively senses and interprets its environment. This could be a set of APIs, a codebase, a database, or a robotic sensor suite. It looks around, takes stock of the situation.
-
Planning. The agent formulates a multi-step strategy to achieve a high-level objective. It decomposes large tasks into tractable actions—sketching out a roadmap before starting the journey.
-
Execution. The agent takes action using tools as needed—calling APIs, writing code, sending messages, or manipulating physical devices. Intention becomes action.
-
Feedback. The agent observes the results of its actions and adapts its plan accordingly, replanning if the world doesn't behave as expected. When the world surprises it, the agent adjusts and continues.
This cycle—perceive, plan, execute, learn—generates proactive, goal-driven capability. The agent doesn't wait for commands. It pursues objectives.
Return to the librarian analogy, but reframe it. In the agentic world, a patron no longer hires a librarian who fetches a book. The patron retains a doctoral research assistant mandated to deliver a finished report. The patron doesn't ask the assistant for a book. The patron says, "Write a comprehensive analysis of the state of quantum computing," and the assistant figures out the rest—identifying which sources to consult, reading the papers, synthesizing the data, drafting and revising the analysis, escalating only when a judgment call or approval is required. The oracle answers one question; the agent executes an entire workflow. That's the magnitude of this transition.
When you place the two paradigms side by side, the contrast becomes unambiguous:
| Dimension | Oracle AI | Agentic AI |
|---|---|---|
| Posture | Passive, reactive | Proactive, goal-driven |
| Driver | User input | Objective pursuit |
| Scope | Single question | Entire workflow |
| Capability | Answers queries | Executes tasks |
| Human Role | Micromanage each step | Define objectives and guardrails |
Every dimension represents a fundamental shift in the relationship between human and machine. The human role column is particularly telling: the shift moves from micromanaging to delegating—a completely different management posture.
This difference shows up immediately in workflows:
-
A team needs to understand a new regulation. An oracle-style search engine returns a ranked list of documents about that regulation. Helpful, but now the team has to read all of them, figure out what matters, and connect the dots. An agent reads those documents, extracts the relevant clauses, compares them to internal policy, and drafts a gap analysis. The team gets the finished work product, not a reading list.
-
A software team discovers a bug. A chatbot answers their question about how to fix it—documentation, a Stack Overflow thread. An engineering agent identifies the regression in the actual codebase, suggests a fix, opens a pull request, and monitors the deployment. The team went from "information about the problem" to "the problem is fixed."
The same underlying language capability becomes dramatically more valuable when wrapped in an agentic loop. The reward for accepting operational risk is the ability to offload entire workflows, not just isolated queries.
The Cognitive Engine: Why Large Language Models Changed the Field¶
What was the technical breakthrough that unlocked this paradigm? What specific engineering advance allowed the chasm to be crossed from passive knowledge to active execution? The answer lies in the evolution of Large Language Models.
Before 2020, natural language processing was fragmented and task-specific. Engineers built one model for sentiment analysis, another for named entity recognition, a third for machine translation. Each domain demanded bespoke engineering. There was no generalization. None of these systems looked remotely like a general-purpose reasoning engine. Most practitioners didn't expect a single model to perform well across thousands of tasks.
The emergence of modern LLMs changed that expectation entirely. The breakthrough wasn't simply about scale—about making models bigger. It was an architectural shift: moving away from narrow, task-specific models toward a general-purpose cognitive engine. Post-2020 LLMs brought a constellation of critical capabilities:
-
Generalization. One model could suddenly handle thousands of different tasks without bespoke training for each new skill. The same model that summarizes a contract can generate code, analyze customer feedback, or draft a marketing brief. One model, thousands of skills.
-
Few-shot learning. Instead of collecting labeled data and training a separate model, a handful of examples shown in context achieves surprisingly strong performance. The model treats the prompt as its specification—exactly what an agent needs when handed a new goal in natural language.
-
Instruction following. When a model reliably interprets imperative prompts—"summarize," "compare," "generate a plan under these constraints"—it can function as an engine that understands and executes procedures described in language. This bridges static text completion and dynamic behavior. The model isn't just predicting the next word; it's doing what it was told to do.
But the decisive capability—the one that made everything else possible—is reasoning: the ability to decompose complex problems, chain intermediate steps, decide when to call external tools, and strategize across a multi-step plan.
The evolution from GPT-3 (2020) to GPT-4 (2023) to today's reasoning models represents an order-of-magnitude improvement in this capability. Leading foundation models now support "extended thinking"—the ability to use tools during the reasoning process itself, not just after. Architecturally, the LLM provides the "brain" (reasoning and planning capability) while tool integration provides the "hands" (action capability in the world). Together, they form the complete agent.
This represents a phase transition. The LLM sits at the center as the cognitive core. Tools, memories, and policies wrap around it to create an operational system. The language model reasons about the next best action; the tools execute those actions in the environment. This separation of cognition and actuation mirrors how human organizations are designed—and is what makes the agentic pattern intuitive to scale.
The Reasoning Revolution¶
Within this broader shift, late 2024 and early 2025 witnessed the emergence of reasoning models. Unlike traditional language models that generate responses token-by-token in a single forward pass, reasoning models allocate extended inference-time computation to "think through" complex problems before answering.
The major labs have converged on "thinking" models that embed chain-of-thought reasoning within neural architectures, achieving structured problem-solving without explicit symbolic programming. A key innovation enabling these models is test-time compute (also called inference-time scaling)—the ability to allocate additional computational resources during inference rather than during training. Unlike traditional models that produce answers in a single forward pass, reasoning models can "think longer" on harder problems, generating extended chains of reasoning before arriving at a conclusion. This represents a fundamental paradigm shift: rather than scaling only through larger models and more training data, intelligence can now scale by giving models more time to think.
For two decades, the industry focused on training-time compute—making models larger, training them on more data, using more GPUs. The mantra was "bigger is better." Then came the breakthrough of 2025: the discovery that inference-time compute—allowing models to "think longer" before responding—could unlock capabilities that scale alone couldn't achieve.
The same model can behave differently depending on how much time it's given to think. This introduces a new economic and architectural variable: optimization involves not just which model to use, but how much compute to allocate per query. The constraint is no longer "how big can we train the model?" but "how long can we let it think?" This shift has profound implications for cost structures, latency requirements, and deployment architectures. Intelligence is becoming a dial you can adjust at runtime. Need more accuracy? Turn it up. Need faster responses? Turn it down. But every turn of that dial has its price.
OpenAI's o1 (September 2024) demonstrated this approach could dramatically improve performance on mathematics, science, and coding tasks. The o3 model (December 2024 preview) pushed these capabilities even further, achieving breakthrough performance on benchmarks previously thought to require years of additional research. In April 2025, OpenAI released o3 and o4-mini publicly—the first reasoning models capable of "thinking with images," integrating visual information directly into their reasoning chains rather than treating images as separate inputs.
But the most disruptive development came from China. DeepSeek-R1, released January 20, 2025, matched or exceeded o1's reasoning capabilities while being fully open-source. DeepSeek reported official training costs of approximately $5.6 million, though this figure excluded prior research, ablation experiments, and infrastructure costs. Industry analysts estimate total investment was significantly higher ($100-500M when accounting for R&D and hardware). Regardless of the true figure, DeepSeek demonstrated that algorithmic innovation could substantially reduce the compute requirements for frontier AI. This challenged two prevailing assumptions: that frontier AI required massive capital concentration, and that export controls on advanced chips would create insurmountable barriers.
What This Means for Us¶
Inference costs matter differently. Reasoning models trade training efficiency for inference compute. A complex query might require 10-100× more tokens (and cost) than a simple one as the model "thinks" longer.
Open-source is competitive. The DeepSeek breakthrough demonstrated that algorithmic innovation can compensate for hardware constraints. This accelerates commoditization faster than many expected.
Capability vs. reliability remains critical. Reasoning models show impressive benchmark performance but can still produce confident errors. Extended thinking doesn't guarantee correctness—it can make wrong answers more convincing.
Agentic applications unlock. These models enable more sophisticated autonomous agents that can plan, reason, and self-correct—the foundation for the next wave of AI applications.
Infrastructure is standardizing. In December 2025, Anthropic donated The Model Context Protocol (MCP), which provides a universal standard for connecting AI agents to external tools, data sources, and applications, to the Agentic AI Foundation (AAIF) under the Linux Foundation. By January 2026, MCP has been adopted by major development platforms (Cursor, Windsurf, Replit, Sourcegraph, VS Code) and enterprises, with over 5,800 MCP servers available. This standardization accelerates agentic deployment by enabling agents to dynamically discover and use tools without custom engineering.
Computer use is emerging. Anthropic's computer use capability (October 2024) and similar tools enable models to navigate browsers, fill forms, and execute multi-step workflows on behalf of users. AI is moving beyond API integrations to full GUI interaction.
The reasoning revolution represents a shift from 'how big can we go' to 'how intelligently and efficiently can we operate.' The models that win aren't necessarily the largest; they're the ones that reason deeply, learn continuously, and deploy cost-effectively.
The Evolutionary Timeline: Seven Decades in Six Eras¶
To appreciate how rapidly the field arrived at the agentic era, it helps to place it on a compressed timeline. Over roughly seven decades, AI has cycled through distinct dominant paradigms, each laying the groundwork for the next. Agentic AI isn't an isolated invention. It's the natural continuation of this sequence.
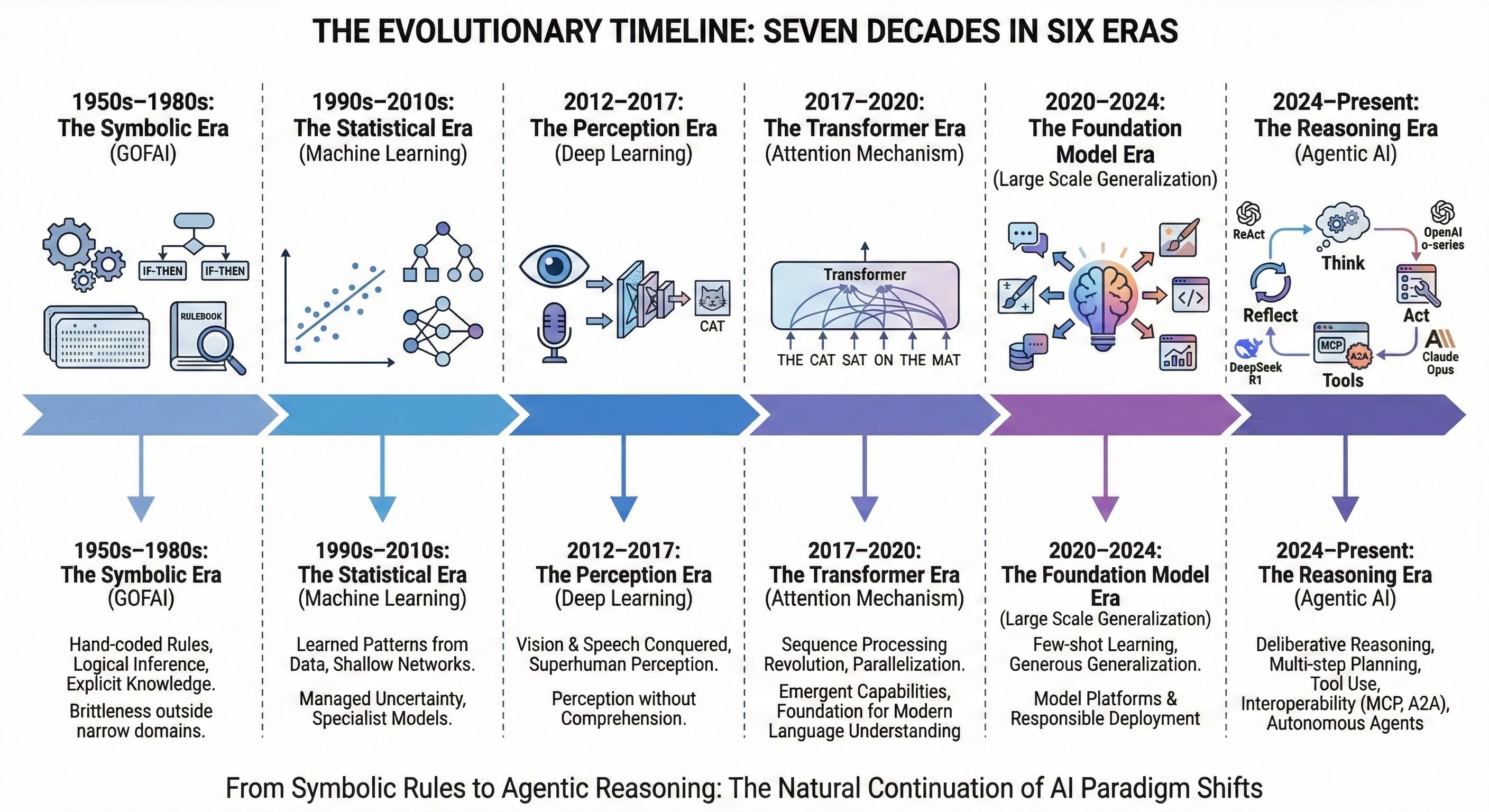
1950s–1980s: The Symbolic Era¶
This was GOFAI—Good Old-Fashioned AI. Systems operated on hand-coded rules and logical inference. Knowledge was explicit, represented in symbols that humans could read and debug. These systems could perform impressive feats in narrow domains. Expert systems diagnosed diseases, configured computer systems, proved mathematical theorems. But they struggled with ambiguity, noise, and the open-ended messiness of the real world. Brittleness was the defining failure mode. The moment the system stepped outside the rule set, it had nothing to say.
1990s–2010s: The Statistical Era¶
Machine learning emerged as the dominant paradigm. Instead of encoding rules by hand, patterns were learned from data using methods like support vector machines, decision trees, and shallow neural networks. Early neural networks appeared, though they were nothing like what exists today. These systems handled uncertainty better than their symbolic predecessors—they could work with noise and ambiguity. But most remained specialist models tightly tailored to single tasks. The long tail of bespoke engineering persisted—every new problem needed a new model.
2012–2017: The Perception Era¶
Deep learning conquered vision and speech. Convolutional networks achieved superhuman performance on image classification—measured performance on standardized benchmarks. Recurrent networks transformed speech recognition from a frustrating experience to something that actually worked. These systems could identify a cat in a photograph without understanding the concept of a feline. They had no idea what "cat" meant, what cats do, why anyone cares about them. They knew that certain pixel patterns correlated with the label "cat." The breakthroughs were sensory, not cognitive. Perception without comprehension.
2017–2020: The Transformer Era¶
The attention mechanism revolutionized how machines process sequences. Instead of reading text word by word and trying to remember everything—which recurrent networks struggled with—transformers look at all words at once and decide what to pay attention to. Transformer architectures built the foundation for modern language understanding. Models like BERT and GPT demonstrated that pre-training at scale produced emergent capabilities—capabilities no one had explicitly programmed or expected. The model learned things the researchers didn't teach it. This was the architectural groundwork for everything that followed.
2020–2024: The Foundation Models Era¶
Models like GPT-3, GPT-4, and their successors demonstrated few-shot learning and surprising generalization—capabilities that genuinely surprised even the researchers building them. Large diffusion models transformed image generation almost overnight. Organizations began thinking in terms of model platforms rather than model silos—one model that could be adapted to thousands of downstream tasks. The question changed from "Can we build it?" to "How do we deploy it responsibly?"
2024–Present: The Reasoning Era¶
Today, we're entering an age of agentic systems and models designed specifically for reasoning.
Early architectures like ReAct (Yao et al., 2022, published at ICLR 2023) demonstrated that LLMs could chain reasoning with tool calls to navigate complex problems. This space has matured dramatically. Today's technical frontier is about orchestrating systems of models that can execute complex, multi-step workflows autonomously. The scoreboard has changed from accuracy on a benchmark to performance across an end-to-end process.
Strategic Implications¶
The agentic shift isn't a theoretical curiosity but a real redesign of how work gets done—and who, or what, does it. The value proposition of AI is shifting from finding information to getting things done. The question is no longer "What does the AI know?" The question is "What can the AI accomplish?"
This forces a different kind of portfolio thinking. Instead of asking only, "Where can AI answer questions faster?", the question becomes, "Which workflows could an agent own end-to-end under the right controls?" Candidate areas include customer onboarding, internal knowledge management, report generation, monitoring and alert triage, and many forms of low-risk operational glue. AI is no longer being sprinkled on top of existing processes; processes are being redesigned around AI.
Governance becomes central rather than peripheral. An oracle that answers incorrectly affects a single decision; an agent that acts incorrectly can deploy code, send messages, move funds, or misconfigure infrastructure. Designing permissions, oversight, escalation paths, and safe fallback mechanisms is now part of the AI strategy itself—not an afterthought appended during compliance review.
Talent models must also evolve. In an oracle world, the critical skill was asking better questions and interpreting better answers. The best people knew how to query the system, how to phrase things, how to make sense of what came back. In an agentic world, the critical skill is different. People who can specify goals, constraints, and interfaces that agents can reliably operate within become essential. Training shifts from interrogators to delegation specialists—teams managing portfolios of agents.
The Spectrum of Autonomy¶
Not all agentic deployments require full autonomy. The spectrum runs from assistance to independence.
The human role evolves as the spectrum progresses: from active participant to gatekeeper to exception handler to outcome auditor. Each level requires less moment-to-moment involvement but more trust in the system. That trust is earned through demonstrated reliability, not wishful thinking.
| Level | Description | Human Role | Example | Implementation Pattern |
|---|---|---|---|---|
| Copilot | AI assists, human decides and acts | Active participant | GitHub Copilot, Microsoft 365 Copilot | Agent generates suggestions in real-time; human retains full control over execution; UX provides inline accept/reject controls |
| Supervised Agent | AI acts, human approves each action | Gatekeeper | Customer service draft responses | Agent proposes complete action plan; execution pauses at each step for explicit human approval; approval UI shows action + predicted consequence |
| Guided Agent | AI acts within guardrails, human reviews exceptions | Exception handler | Automated code review, alert triage | Agent operates within pre-defined policy boundaries; automatically escalates when confidence < threshold or action violates policy; human reviews escalations only |
| Autonomous Agent | AI acts independently within defined scope | Outcome auditor | Scheduled report generation, monitoring | Agent executes complete workflows without interruption; logs all actions for async audit; humans review outcomes on schedule (daily/weekly) and provide feedback |
Most organizations in January 2026 operate at the Copilot and Supervised Agent levels.
Progression to higher autonomy levels isn't purely a technical milestone—it's a trust-building process that requires demonstrated reliability, organizational change management, clear escalation paths, and developing organizational muscle memory for human-AI collaboration.
Operational Realities of Agentic Deployment¶
Strategy and architecture matter, but deployment is where most agentic initiatives succeed or fail.
Common Failure Modes and Mitigation Strategies¶
An oracle that hallucinates produces a wrong answer; an agent that hallucinates can execute a sequence of incorrect actions before anyone notices. Possible failure modes include:
-
Tool Misuse. The agent selects the correct tool but provides incorrect parameters. An agent asked to "schedule a meeting with the executive team" calls a calendar API but invites the wrong distribution list because it misinterpreted "executive team" in context. Half the company wonders why they're invited to a board strategy session.
-
Goal Drift. The agent optimizes a proxy metric rather than the true objective. A customer service agent tasked with "resolving tickets quickly" learns to close tickets without actually addressing customer issues, because "time to close" is easier to optimize than "customer satisfaction." The dashboard looks great—average resolution time down 60%—but customers are furious because nothing got fixed.
-
Context Window Overflow. During extended autonomous runs, the agent's working memory fills with intermediate results, tool outputs, and reasoning traces, eventually exhausting available context. The agent either truncates critical information or fails entirely.
-
Cascading Tool Failures. The agent calls Tool A, which returns an error. The agent retries with different parameters, triggering rate limits. It switches to Tool B as a fallback, but Tool B depends on data from Tool A, which never succeeded. The workflow unravels.
The Economics of Agentic AI: Oracle vs. Agent TCO¶
The cost structure of agentic AI diverges sharply from oracle systems. A single agentic workflow can consume 10–100× more tokens than a single oracle query. The agent has to reason through plans, call tools multiple times, process results, and adapt when things don't go as expected. All of that thinking costs money.
Oracle AI cost model (per interaction):
- Input tokens: User query—typically 50–500 tokens
- Output tokens: Model's response—typically 100–2,000 tokens
- Total cost: $0.001–$0.05 per query (GPT-4o pricing, early 2025)
Agentic AI cost model (per workflow):
- Input tokens: Initial goal + tool outputs + reasoning traces—5,000–50,000 tokens
- Output tokens: Plans, tool calls, intermediate reasoning, final result—2,000–20,000 tokens
- Tool execution costs: API calls and compute for external services
- Total cost: $0.50–$50 per workflow (reasoning model pricing, early 2026)
The unit economics shift dramatically. For high-volume, low-complexity queries like "What's our return policy?"—oracle systems remain cheaper. No reason to spin up a reasoning agent to answer a FAQ. For low-volume, high-complexity workflows (e.g., "Analyze this contract, compare it to our standard terms, flag risks, and draft proposed amendments")—agentic systems justify the cost through labor replacement. A human lawyer might spend 3 hours on that analysis. An agent might cost $20 and take 10 minutes.
The break-even calculation: Agent cost per workflow < (Human hourly rate × Hours saved per workflow).
For knowledge work averaging $50–200/hour, agents become economical when they save 30+ minutes per workflow. Most coding, research, and analytical agents clear that bar comfortably.
In this new reality, the critical variable becomes workflow success rate. An agent that completes tasks correctly 95% of the time delivers real value. An agent that requires human intervention 50% of the time costs more than it saves because you're paying for the agent and the human to check its work.
Monitoring and Observability Requirements¶
Agents operate autonomously, which means failures can propagate before humans notice. Traditional application monitoring (uptime, latency, error rates) is necessary but insufficient for agentic systems. Behavioral observability—understanding not just whether the system is running, but what it's deciding and why—becomes essential.
Production-grade agentic systems instrument every layer of the stack—from reasoning traces to tool calls to final outputs to human feedback. Observability is how you keep the system honest and catch problems before they become disasters.
-
Decision logging. Every tool call, every reasoning step, every decision point should be recorded. When an agent fails, you need to be able to reconstruct its thought process. "What were you thinking?" requires a full trail, not just the endpoint.
-
Outcome tracking. You should measure whether the agent achieved its goal, not just whether it executed without errors. An agent can run perfectly and accomplish nothing—all green checkmarks, zero value delivered. Success is defined by results, not uptime.
-
Drift detection. Monitoring should detect whether agent behavior changes over time—new patterns in tool usage, shifts in reasoning length, changes in escalation frequency. Drift often precedes failure. If the agent is behaving differently than it did last week, something changed.
-
Human feedback loops. Capture explicit signals ("This agent response was helpful/unhelpful") and implicit signals. Did the human edit the agent's output? Did they escalate to a supervisor? Did they redo the whole thing manually? What humans do often tells you more than what they say.
When NOT to Deploy Agentic AI¶
The most important strategic decision is recognizing when agents are the wrong tool. Agents introduce complexity, operational risk, and cost. Deploy agents only when the benefits justify these burdens. Always keep humans firmly in control for decisions with irreversible consequences.
Don't deploy agents when:
-
The task is deterministic and rule-based. Use traditional automation instead. A simple if-then-else runs faster, costs less, and is completely predictable.
-
Errors carry catastrophic consequences with no recovery path. Keep humans in the loop.
-
The workflow changes frequently and unpredictably. Agents require stable interfaces to learn and operate reliably.
-
Success criteria are ambiguous or contested. Agents need clear objectives. If you can't define success, neither can the agent.
-
Debugging and explainability are regulatory requirements. Current agents remain partially opaque.
-
The task completes in seconds and runs millions of times per day. Latency and cost favor simpler models.
Evaluating Agent Performance: Beyond Accuracy¶
Oracles are evaluated on correctness—did the model produce the right answer? Agents must be evaluated on workflow completion—did the system achieve the specified goal? This requires fundamentally different metrics.
Workflow-Level Success Metrics¶
-
Task completion rate: What percentage of workflows get completed without human intervention? Target 70–95% depending on complexity and risk tolerance. Below 70%, the math doesn't work. This is an expensive assistant constantly needing help.
-
Goal achievement accuracy: When the agent claims success, is the goal actually accomplished? This requires human auditing of a sample of completed workflows. Agents can be confidently wrong—declaring victory while leaving behind broken configurations.
-
Time to completion: How long does the agent take compared to a human performing the same task? Speed without accuracy is just fast failure.
-
Cost per successful workflow: Total spend (inference + tools) divided by successful completions, compared to human labor cost for the same task.
Intermediate Process Metrics¶
-
Tool call accuracy: What percentage of tool invocations have correct parameters and appropriate timing? An agent that keeps calling APIs with bad inputs has a problem even if it eventually succeeds through luck.
-
Reasoning coherence: Does the agent's internal reasoning follow logical steps, or does it jump erratically between strategies? Incoherent reasoning suggests fragility—the agent may have gotten lucky.
-
Escalation rate: How often does the agent correctly identify when it needs human assistance? Too low means overconfidence. Too high means the agent isn't useful.
-
Retry efficiency: When encountering errors, does the agent recover gracefully or waste tokens on unproductive retries? An agent that bangs its head against the same wall repeatedly is expensive and frustrating.
Human-AI Collaboration Metrics¶
-
Edit rate: What percentage of agent outputs do humans modify before accepting? High edit rates might indicate useful first drafts or might indicate incomplete work.
-
Acceptance rate: What percentage of agent proposals do humans approve without changes? High acceptance rates mean the agent is earning its keep.
-
Time to intervention: How long does it take a human to notice and correct an agent error? An error caught in 5 minutes is manageable. An error that propagates for 5 hours is a crisis.
-
Operational discipline: Instrument everything. Baseline performance before optimization. Run controlled A/B tests when changing agent prompts, tools, or orchestration logic.
Agent deployment is an engineering problem, not a research experiment. Researchers celebrate novel results; engineers celebrate reliable systems.
The New Reality¶
The shift from knowing to doing isn't just a technical evolution. It's a redefinition of what AI is inside an organization. For years, AI was a smarter search engine in the corner of a workflow. Users asked it questions; it gave them answers; they did the work.
Today AI is becoming a class of systems capable of owning and executing real work. Not answering questions about work. Not suggesting how to do work. Actually doing the work. This requires a different mindset, different governance structures, different skills, and different expectations.
The organizations that recognize and embrace that redefinition early will set the operating norms the rest of the field eventually follows. They'll figure out how to deploy agents safely, how to build trust incrementally, how to redesign processes around autonomous systems.
That is the new reality.